
여드름 탐지 데이터의 전처리를 수행했던 이전 글에 이어, 이번 글에서는 object detection 모델 학습을 진행해 보려고 합니다. 두 포스팅을 분리하여 올리는 이유는, 글의 분량 문제도 있지만 Training 과정을 좀 더 상세하게 서술하고 싶다는 이유였습니다.
단순히 학습 과정을 나열하기보다, 그 과정에서 발생했던 문제점들과, 그에 대처한 이야기를 전달하고 싶었습니다. 조금 긴 글이 되겠지만, 이번 프로젝트를 진행하며 배우고 느낀 것을 최대한 담으려고 노력했습니다. 이번 글 역시 코드 위주로, data augmentation, training and validation, test 과정을 다루어 보겠습니다.
1. Data augmentation
def train_aug(inputs,targets):
for i in range(len(inputs)):
_,h,w = inputs[i].shape
hflip = random.random()>0.5
if hflip:
inputs[i] = T.functional.hflip(inputs[i])
targets[i]['boxes'][:,0], targets[i]['boxes'][:,2] = w - targets[i]['boxes'][:,2], w - targets[i]['boxes'][:,0]
vflip = random.random()>0.5
if vflip:
inputs[i] = T.functional.vflip(inputs[i])
targets[i]['boxes'][:,1], targets[i]['boxes'][:,3] = h - targets[i]['boxes'][:,3], h - targets[i]['boxes'][:,1]
return inputs,targets각각 0.5의 확률로 좌우/상하 반전을 수행하는 augmentation입니다. torchvision.transformations 라이브러리를 활용하였으며, 이미지를 뒤집으면서 동시에 bounding box 좌표도 변환해 주었습니다.
inputs는 list of tensor 의 형태를 하고 있으며, targets는 list of dictionary의 형태로, 'boxes'와 'labels' key를 갖고 있습니다. data augmentation을 수행한 뒤, 같은 형태의 output을 내보냅니다.
2. Training / Validation
이번 프로젝트에서 학습에 사용된 모델은 torchvision.models.detection 라이브러리의 fasterrcnn_resnet50_fpn 모델입니다. 해당 모델은 resnet - 50을 backbone network로 하여 fpn기법을 통해 5개의 feature map을 산출하고, 이를 detection task에 활용하는 모델입니다.
Training / Validation에 대해서는, 학습 과정에서 발생했던 다양한 시행착오들을 먼저 밝히고, 그에 대한 조정을 거쳐 결정된 모델의 형태를 진술하려고 합니다. 이후, 4가지의 서로 다른 학습 전략을 비교하여 최종 모델을 산출하고, test를 진행해 보겠습니다.
2. 1. 시행착오
먼저, 생각할 수 있었던 가장 단순한 모델은 이러한 형태였습니다.
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1)사전 학습된 모델을 불러와 재학습시키는 단순한 형태입니다. 처음에는, 데이터셋의 특성에 대한 충분한 고려가 없기 때문에, 이 방식은 제대로 된 성능을 내기 어려울 것이라고 생각했습니다.
그래서 데이터셋의 특성 (이미지의 크기, bounding box의 평균 크기)를 고려한 다음과 같은 학습 방식을 사용해 보았습니다.
anchor_sizes = ((8,), (16,), (24,), (32,), (40,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorGenerator(anchor_sizes, aspect_ratios)
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1, rpn_anchor_generator = anchor_generator, min_size = 350, rpn_batch_size_per_image = 100, box_batch_size_per_image = 100)anchor generator는 feature map의 각 location들을 기준으로, 원본 image에 grid를 생성합니다. 이후, 지정된 크기와 종횡비의 anchor boxes를 생성합니다. 해당 모델의 디폴트 anchor size는 (32, 64, 128, 256, 512) 인데, 한 변이 평균 16에 불과한 데이터셋의 bounding box 크기를 생각하면 터무니없는 크기의 anchor size라고 생각되었습니다.
구체적으로 설명하면, 디폴트 anchor box의 크기가 너무 커 제안된 대부분의 anchor box가 negative sample로 분류될 것을 예상했습니다. 그래서 (8, 16, 24, 32, 40)의 anchor size를 채택하여 학습을 진행해 보았습니다.
(size를 5개로 고정한 이유는, backbone의 resnet50_fpn이 5개의 feature map을 산출하기 때문에, 그 개수에 size의 개수를 맞추어야 오류가 발생하지 않기 때문입니다.)
또한, 데이터셋의 negative example로의 편향을 줄이기 위해, 한 image에서 학습에 채용하는 anchor box의 총 개수를 100으로 감소시켰습니다. rpn 학습에 사용되는 positive / negative box의 비율은 고정되어 있지만, positive example이 부족한 경우 negative example로 그 자리를 채우게 되어 있기 때문입니다. 따라서 데이터셋의 편향이 일어날 수 있습니다.
마지막으로, 모델 학습이 예상한 대로 진행되도록 하기 위해, 디폴트가 800인 resize 크기를 350으로 설정했습니다. image size와 box size가 변동하지 않도록 하기 위함이었습니다. (collate_fn 에서 제가 설정한 resize 크기가 350이었습니다.)


이렇게 고유한 특성을 고려하여 수정된 training 세팅은, 제 데이터셋에 잘 최적화될 것으로 보였습니다. 적어도 단순히 모델을 불러오기만 했던 기존 세팅보다는 더 좋은 성능을 보일 것이라고 생각했죠. 하지만, 위 그림에서 보이듯, 수정된 training setting은 기존의 세팅보다 더 '바람직하지 않게' 행동했습니다.
다수의 여드름을 잡아내기보다 하나의 여드름에 많은 box가 집중되는 경향을 보였으며, 기존 세팅의 모델에서 탐지했던 여드름을 놓치기도 했던 것입니다. 예상치 못한 결과에, 이런 현상이 벌어진 이유를 고민하게 되었습니다. 제가 분석한 내용은 다음과 같습니다.
수정된 세팅과 기존 세팅의 가장 큰 차이점은 '이미지의 크기' 입니다. faterrcnn_resnet50_fpn 모델은 이미지를 backbone에 투입하기 전 normalization, resize 등의 transformation을 수행합니다. 이 과정에서 기존 모델은 800의 size로 이미지를 resize하게 됩니다.
이때, bounding box의 크기 역시 변동하게 되고, 두 배 이상 커진 bounding box를 예상하는 데에 기존 모델의 (32, 64, 128, 256, 512) anchor box size는 더 이상 비합리적이지 않습니다. 가장 촘촘한 anchor grid를 형성할 32, 64 size의 박스들 때문이죠.
결국, 두 모델은 다른 크기의 이미지를 사용한다는 차이점만 가질 뿐, 기본적으로 비슷한 환경에서 학습과 예측을 진행하게 되는 것입니다. 그렇다면, 더 큰 이미지를 활용한 학습이 갖는 이점은 무엇이 있을까요?
첫째, 더 많은 수의 anchor box가 제안됩니다. image가 커지면, 산출되는 feature map의 크기도 커지고, anchor box의 기준점인 grid의 개수도 많아지기 때문입니다. 더 많은 anchor box는 더 많은 positive example을 만들어내고, 한 이미지에서 학습에 채용되는 box의 개수도 더 높일 수 있게 됩니다. 즉, 실질적인 데이터량이 증가하는 것입니다.
둘째, 더 촘촘한 location에서 학습을 진행할 수 있습니다. Faster R - CNN은 feature map 위 각각의 location을 중심으로 학습을 진행합니다. 따라서, feature map의 사이즈가 커지면 한 이미지에서 학습이 일어나는 지점이 더 많아지고, 촘촘해지게 됩니다. 특히, 여러 개의 작은 지점들이 발생하는 여드름 탐지의 경우에 이는 더욱 큰 도움이 될 것입니다.
마지막으로, pretrained weights의 성능을 최대한 활용할 수 있습니다. 저희는 극히 적은(약 100개의) 데이터셋을 가지고 학습을 진행하고 있기 때문에, 사전 학습된 환경에 잘 따르는 것이 중요합니다. 따라서 디폴트 image size를 선택하는 것이 학습에 유리합니다.
2. 2. 최종 모델
anchor_sizes = ((32,), (48,), (64,), (80,), (96,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorGenerator(anchor_sizes, aspect_ratios)
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1,
rpn_anchor_generator = anchor_generator)이와 같이 일련의 시행착오를 거친 후, 결정된 최종 모델은 위와 같습니다. 모델의 디폴트 image size를 사용했고, 데이터셋의 box size에 맞게 anchor box size만을 약간 조정했습니다. 추가로, 중복된 resize를 수행할 필요가 없기 때문에 collate_fn의 resize 과정을 삭제했습니다.
#fixed collate_fn
def my_collate(batch):
img_list = []
target_list = []
train = False
if len(batch[0]) == 2: train = True
for data in batch:
if train:
img,target = data
converted_target = {}
converted_target['labels'] = torch.tensor(target['labels'])
converted_target['boxes'] = torch.tensor(target['boxes'])
img_list.append(img/255)
target_list.append(converted_target)
else:
img_list.append(data/255)
if not train: return img_list
return img_list,target_list
2. 3. training and validation
def train(model, epochs, optimizer):
model.to(device)
train_errors = []
val_errors = []
for epoch in range(epochs):
model.train()
print(f'Epoch {epoch+1}/{epochs}')
print('-' * 10)
epoch_loss = 0
for batch, (inputs,targets) in enumerate(train_dataloader):
inputs,targets = train_aug(inputs,targets)
imgs = []
targs = []
for i in range(len(inputs)):
targ = {}
imgs.append(inputs[i].to(device))
targ['boxes'] = targets[i]['boxes'].to(device)
targ['labels'] = targets[i]['labels'].to(device)
targs.append(targ)
loss_dict = model(imgs,targs)
loss = loss_dict['loss_classifier'] + 10*loss_dict['loss_box_reg'] + loss_dict['loss_objectness'] + 10*loss_dict['loss_rpn_box_reg']
epoch_loss += loss.cpu().detach().numpy()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_errors.append(epoch_loss/105)
print(f'epoch loss = {epoch_loss/105}')
#validation
epoch_valerror = 0
for batch, (inputs,targets) in enumerate(val_dataloader):
imgs = []
targs = []
for i in range(len(inputs)):
targ = {}
imgs.append(inputs[i].to(device))
targ['boxes'] = targets[i]['boxes'].to(device)
targ['labels'] = targets[i]['labels'].to(device)
targs.append(targ)
with torch.no_grad():
loss_dict = model(imgs,targs)
loss = loss_dict['loss_classifier'] + 10*loss_dict['loss_box_reg'] + loss_dict['loss_objectness'] + 10*loss_dict['loss_rpn_box_reg']
epoch_valerror += loss.cpu().detach().numpy()
val_errors.append(epoch_valerror/30)
print(f'validation loss = {epoch_valerror/30}')
print(' ')
return train_errors, val_errorsDetection 모델 학습에 사용한 코드입니다. 1 epoch마다 validation을 수행했고, 동등한 비교를 위해 loss를 각 데이터셋 사이즈로 나눠 주었습니다.
training 모드의 fasterrcnn 모델은 image와 target을 입력받아 4가지의 loss를 산출합니다. rpn에서는 objectness loss (background / object 분류), rpn box regression loss를 산출하고, roi_head에서는 classification loss (모든 클래스 분류), box regression loss를 산출합니다.
이때, 총 loss의 계산은 box regression loss에 10을 곱하는 원 논문의 방식에 따랐습니다.
2. 3. 0. 학습 전략
프로젝트의 한정된 데이터셋의 크기를 고려했을 때, 작은 크기의 데이터셋을 효과적으로 활용할 학습 전략을 찾아내는 것이 중요합니다. 그래서 저는 4가지의 서로 비교할 만한 학습 전략들을 세웠습니다. 이제 각 전략의 validation loss를 비교한 뒤, 가장 좋은 결과를 낸 학습 방법을 알아보겠습니다.
- vanila training : 모델 전체를 8회 학습시킵니다. learning rate = 1e-5 인 Adam optimizer를 사용했습니다.
- learning rate decay : lr = 1e-5로 8회 학습시킨 뒤, lr = 1e-6으로 8회 학습시킵니다.
- finetuning : 모델 전체를 6회 학습시킨 후, backbone network의 weights를 얼립니다. 이후, rpn과 roi_head의 weights만을 2회 학습시킵니다. (lr = 1e-5)
- alternate finetuning : 원 논문에서 제안된 학습 방식입니다. rpn을 3회 학습한 뒤, roi_head를 3회 학습하고, 이후 동시에 finetuning을 2회 진행합니다. (lr = 1e-5)
2. 3. 1. vanila training
#train1 : vanila
device = torch.device('cuda:0')
anchor_sizes = ((32,), (48,), (64,), (80,), (96,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorGenerator(anchor_sizes, aspect_ratios)
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1,
rpn_anchor_generator = anchor_generator)
num_classes = 3
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
epochs = 8
optimizer = optim.Adam(model.parameters(),lr = 1e-5)
t_e,v_e = train(model,epochs,optimizer)
train1_errors = [t_e,v_e]데이터셋이 2가지의 class (spot, region)으로 이루어져 있기 때문에, background class를 포함한 3개의 class로 학습을 진행합니다. 1e-5의 learning rate를 갖는 Adam optimizer를 사용했습니다.
training / validation error는 다음과 같았습니다. 최종 validation error는 약 1.9를 기록했습니다.

2. 3. 2. learning rate decay
#train2 : learning rate decay
device = torch.device('cuda:0')
anchor_sizes = ((32,), (48,), (64,), (80,), (96,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorGenerator(anchor_sizes, aspect_ratios)
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1,
rpn_anchor_generator = anchor_generator)
num_classes = 3
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
train2_errors = [[],[]]
#train 8 epochs with lr = 1e-5
epochs = 8
optimizer = optim.Adam(model.parameters(),lr = 1e-5)
t_e,v_e = train(model,epochs,optimizer)
train2_errors[0] += t_e
train2_errors[1] += v_e
#train 8 epochs with lr = 1e-6
epochs = 8
optimizer = optim.Adam(model.parameters(),lr = 1e-6)
t_e,v_e = train(model,epochs,optimizer)
train2_errors[0] += t_e
train2_errors[1] += v_e앞에서 설명한 대로, 8 epochs는 1e-5의 learning rate로, 그다음 8 epochs는 1e-6의 learning rate로 학습을 진행했습니다.
training / validation error는 다음과 같았습니다. 최종 validation error는 1.9정도로, vanila training과 유의미하게 다른 결과를 보이지는 않았습니다.
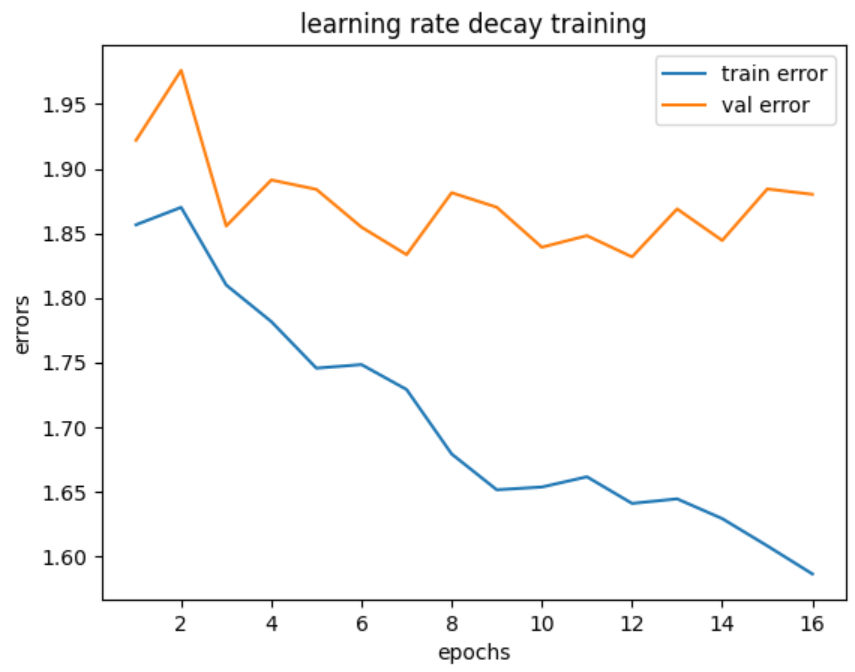
2. 3. 3. Finetuning
#train3 : finetuning
device = torch.device('cuda:0')
anchor_sizes = ((32,), (48,), (64,), (80,), (96,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorGenerator(anchor_sizes, aspect_ratios)
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1,
rpn_anchor_generator = anchor_generator)
num_classes = 3
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
train3_errors = [[],[]]
optimizer = optim.Adam(model.parameters(),lr = 1e-5)
# train whole network 6 epochs
epochs = 6
t_e,v_e = train(model,epochs,optimizer)
train3_errors[0] += t_e
train3_errors[1] += v_e
#finetune 2 epochs
for param in model.parameters():
param.requires_grad = False
params_wo_backbone = [param_name for param_name in model.state_dict().keys() if param_name[0] != 'b']
for name,param in model.named_parameters():
if name in params_wo_backbone:
param.requires_grad = True
epochs = 2
t_e,v_e = train(model,epochs,optimizer)
train3_errors[0] += t_e
train3_errors[1] += v_e6 epochs는 네트워크 전체를, 그다음 2 epochs는 backbone network를 얼린 채 finetuning을 진행했습니다.
training / validation error는 다음과 같았습니다. 최종 validation error는 1.8정도로, vanila training에 비해 조금 향상된 성능을 보여 주고 있습니다.

2. 3. 4. Alternating training
#train4 : alternating finetuning
device = torch.device('cuda:0')
anchor_sizes = ((32,), (48,), (64,), (80,), (96,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
anchor_generator = AnchorGenerator(anchor_sizes, aspect_ratios)
model = models.detection.fasterrcnn_resnet50_fpn(weights = FasterRCNN_ResNet50_FPN_Weights.COCO_V1,
rpn_anchor_generator = anchor_generator)
num_classes = 3
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
train4_errors = [[],[]]
optimizer = optim.Adam(model.parameters(),lr = 1e-5)
#train rpn : 3 epochs
params_roi = [param_name for param_name in model.state_dict().keys() if param_name[:3] == 'roi']
for name,param in model.named_parameters():
if name in params_roi:
param.requires_grad = False
epochs = 3
t_e,v_e = train(model,epochs,optimizer)
train4_errors[0] += t_e
train4_errors[1] += v_e
#train roi_heads : 3 epochs
for name,param in model.named_parameters():
if name in params_roi:param.requires_grad = True
params_rpn = [param_name for param_name in model.state_dict().keys() if param_name[:3] == 'rpn']
for name,param in model.named_parameters():
if name in params_rpn:param.requires_grad = False
epochs = 3
t_e,v_e = train(model,epochs,optimizer)
train4_errors[0] += t_e
train4_errors[1] += v_e
#finetune both : 2 epochs
for param in model.parameters():
param.requires_grad = False
params_wo_backbone = [param_name for param_name in model.state_dict().keys() if param_name[0] != 'b']
for name,param in model.named_parameters():
if name in params_wo_backbone:param.requires_grad = True
epochs = 2
t_e,v_e = train(model,epochs,optimizer)
train4_errors[0] += t_e
train4_errors[1] += v_e3 epochs는 rpn (+backbone)을, 그다음 3 epochs는 roi_head (+backbone)을 학습하고, 마지막으로 backbone network를 얼린 채 finetuning을 진행했습니다.
training / validation error는 다음과 같았습니다. 최종 validation error는 1.8정도로, finetuning과 비슷한 성능을 보였습니다.

2. 3. 5. 학습 전략 비교
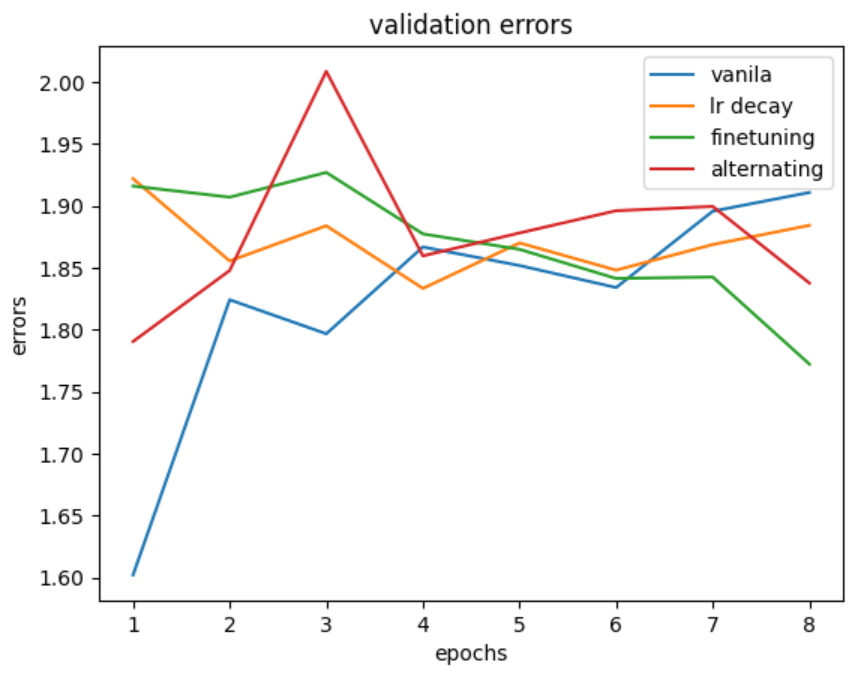
학습 전략 간의 비교를 위해, 각 validation error를 한눈에 볼 수 있도록 정리해 보았습니다. 각 전략 간의 극적인 성능 차이는 보이지 않았지만, 3번째의 finetuning 전략은 최종 validation error가 가장 낮으며 그 값이 안정적으로 감소하는 형태를 보였습니다. 따라서 vanila training에 finetuning을 추가한, 3번째 전략이 가장 효율적이었다고 말할 수 있겠습니다.
따라서, 3번째 (vanila + finetuning) 전략을 최종 학습 방식으로 선택하겠습니다. 다만, 이어질 test에 사용된 모델은 finetuning 과정의 횟수를 추가해 총 6번의 전체 training과 6번의 finetuning을 거쳤음을 알려 드립니다.
3. Test
이제, 모델에 새로운 데이터를 투입하고, inference를 수행하여 그 탐지 능력을 평가해 보겠습니다. 과연 모델이 우리가 의도한 대로 잘 행동할까요? 이를 잘 평가하려면 먼저 모델에 대한 우리의 '의도'가 어떤 것인지 확실히 짚고 넘어갈 필요가 있는 것 같습니다.
앞서 포스팅했던 'Roboflow를 이용한 data annotation' 에서, bounding box annotation을 진행하며 모델의 방향성을 고민했던 일이 있습니다. 이때 저는 다음과 같은 annotation 기준을 세웠습니다.
- 첫째, 밀집되어 구분할 수 없는 여드름은 하나의 구역(region)으로 묶습니다. 그 중에서도 구분되는 head는 따로 표시합니다.
- 둘째, 고름이 보여 head를 식별할 수 있는 여드름과, 눈에 띄게 부어올라 확실하게 구분할 수 있는 여드름만 선택하여 box를 칩니다.
위의 기준을 세움으로써, 제 데이터셋을 학습한 모델이 적어도 '확실한 여드름만큼은 잘 포착할 수 있는 능력'을 갖게 되기를 기대했습니다. 평가 단계에서는 모델이 이런 최초의 의도를 잘 따르고 있는지 확인하면 될 것 같습니다. 이제, 여러 개의 inference 결과물을 살펴보며, 사례 중심으로 모델이 어떻게 행동하고 있는지를 조사해 보겠습니다.
examples_1




위의 사례들을 보면, 기본적으로는 모델이 의도대로 잘 행동하고 있는 것을 알 수 있습니다. 여드름의 흔적이나 흉터로 보이는 애매한 부분들을 배제하고, 확실히 부어오르거나 고름이 차 있는 여드름들을 골라 탐지하고 있기 때문입니다. 모든 여드름을 빠짐없이 탐지한 것은 아니지만, 이 정도면 훌륭한 inference를 수행했다고 할 수 있을 것 같습니다.
대부분의 사례에서, 우리의 모델은 이와 같은 준수한 성능을 보여 주고 있었습니다. 하지만, 몇몇 사례에서는 모델의 약점을 발견할 수 있었습니다.
examples_2


위의 사례들을 볼 때, 모델이 탐지하지 못한 여드름들은 한 가지 공통된 특징이 있었습니다. 바로, 중앙에 head를 갖지 않은 채 부어오른 여드름들이라는 것입니다. 즉, 6가지 여드름의 종류 중 'papule'과 'nodule'을 잘 탐지하지 못하는 것입니다.
한편, 여드름보다는 그 흔적에 가까운 작은 점들을, 여드름으로 탐지하고 있는 것을 알 수 있습니다. 따라서, 우리 모델의 약점은 'acne head의 형태에 너무 집중한다는 것' 이라고 할 수 있습니다.
이러한 현상이 벌어진 이유를 추측해 보면, annotation 과정에서 그 원인을 찾을 수 있을 것 같습니다. 저는 피부과 전문 지식이 없기 때문에, 여드름 상처나 피부의 요철을 실제 여드름과 잘 구분하지 못합니다. 그래서 annotation 당시 제가 확실히 판별할 수 있는 여드름만을 선택해 annotation을 진행했습니다. 그러다 보니 눈에 띄는 head를 갖는 여드름 위주로의 데이터 편향이 발생한 것 같습니다.
examples_3




이외에 몇 가지 사례들을 더 첨부합니다. 학습된 모델은 대체로 꽤나 준수한 성능을 보여 주고 있습니다만, 귀걸이 등 점 모양 물체를 여드름으로 잘못 탐지하거나, 여드름이 뭉친 'region' 클래스를 산출하지 못하는 점 등의 약점들이 발견되었습니다. 아마도 이는 데이터량의 부족으로 인한 것으로 해석됩니다.
마치며
이 프로젝트는 데이터 준비에서부터 모델 학습과 평가까지, 혼자서 모든 단계를 만들어간 첫 프로젝트였습니다. 그런 만큼 많은 시행착오를 겪었고, 또 Faster R - CNN 모델 학습에 대해 몇 가지 논의할 만한 점들도 발견했습니다. 포스팅의 마무리는 이번 프로젝트에서 추가로 생각할 만했던 점들을 써보려고 합니다.
- 첫째, loss의 문제입니다. 다양한 세팅으로 수차례 학습을 돌려 본 결과, validation loss가 더 작다고 해서 더 좋은 모델이 되는 것은 아니었습니다. 일례로, 전체 모델에 대한 학습 없이 finetuning만 진행한 모델은 그 validation loss가 0.5 수준으로 매우 낮았지만, 산출되는 detection score가 매우 작아 탐지되는 여드름 수 자체가 극히 적었습니다. 그래서 모델을 평가할 때, loss가 적당히 낮은 것과 더불어 실제 결과물을 살펴보는 것이 중요했습니다.
- 둘째, 해당 필드에 대한 전문 지식의 중요성입니다. 데이터셋 준비 과정과 모델 평가 과정에서 그 필요를 절감하게 되었는데, 인공 지능 모델이 사용될 분야에 대한 기초적인 지식이 있어야 더 적절하고 쓸모있는 모델을 만들 수 있을 것 같았습니다. 저는 여드름의 종류를 분류할 줄도 모르고, 나아가 피부과 의사들에게 진짜로 필요한 기능이 어떤 것인지를 모릅니다. 그래서 모델 개발의 방향을 잡을 때 많은 어려움을 겪었고, 결국 몇 가지 한계점이 있는 모델을 만들게 되었습니다.
- 셋째, 모델 개발에 대한 이해도 중요합니다. 처음 anchor box size를 수정할 때, backbone network인 resnet50_fpn 모델의 output 형태를 생각하지 않아 디버깅에 어려움을 겪었던 일이 있습니다. 이때 fpn의 개념과 pytorch의 source code를 한참 공부하고 나서야 겨우 구조를 이해하고 버그를 해결했었습니다. 이외에도 수많은 시행착오가 있었고, 그 해결책은 항상 원 논문과 source code 공부에서 얻어냈습니다.
참고문헌
1. Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2016)
2. pytorch source codes (faster_rcnn, generalized_rcnn, rpn, roi_heads ...)
3. herbwood - FPN 논문(Feature Pyramid Networks for Object Detection) 리뷰
4. towardsdatascience - How to Annotate Keypoints Using Roboflow
'projects' 카테고리의 다른 글
| Faster R-CNN을 이용한 여드름 탐지 - 데이터 전처리 (2) | 2023.09.30 |
|---|---|
| Roboflow를 이용한 data annotation (0) | 2023.09.13 |
| 여드름을 찾아내는 AI가 있다면 (0) | 2023.08.30 |
| Keypoint detection - 사람의 위치와 자세를 추정한다 (0) | 2023.07.08 |
| 천릿길도 한 걸음부터 (0) | 2023.07.05 |